|
|
2.6 多提示集成mpt Learning for News Recommendation
地址:https://arxiv.53yu.com/pdf/2304.05263.pdf
代码:https://github.com/resistzzz/Prompt4NR
会议:SIGIR 2023
学校:华中科技大学 1. 导读
本文介绍了一个新的面向新闻推荐的框架,称为Prompt4NR,该框架采用了一种称为prompt learning的预训练、提示和预测范式。在这个框架中,任务被转化成一个填空式掩码预测任务,通过设计一系列提示模板和相应的答案空间,以充分利用预训练过程中嵌入的丰富语义信息和语言知识。
2. 方法
2.1 总览
将用户集与新闻集分别表示为和。每个新闻主要包含其标题,它是一个词序列,其中M是单词数量。给定用户u的点击历史,其中包含了L篇被点击的新闻以及一个候选新闻,新闻推荐(NR)任务旨在预测排名分数,以估计用户u是否会点击候选新闻的概率。具有最高分数的候选新闻将被推荐给用户。
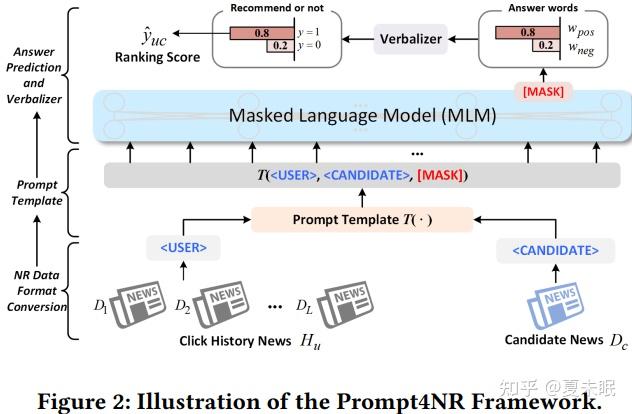
图2说明了Prompt4NR框架,其中包含三个主要模块:(1)NR数据格式转换;(2)Prompt模板;(3)答案预测和词面实现。
2.2 数据格式转换
给定一个点击历史记录 _ 和候选新闻 _ ,将它们转换成一个自然语言句子,以适应后续的Prompt学习范式,分别表示为< USER >和< CANDIDATE >。对于< USER >,将一个用户历史记录 _ 中新闻的标题连接起来,其中在每个标题的开头添加一个虚拟标记[NCLS],以分割每个被点击的新闻。对于< CANDIDATE >,采用候选新闻D_c的标题。表示为:
< USER > ← [NCLS] 1 ... [NCLS]
< CANDIDATE > ←
其中\{ _1,..., _ \}对应于 _ =\{ _1, _2,..., _ \}中的新闻标题。< USER >可以被看作是用户 的兴趣的摘要,而< CANDIDATE >则概括了候选新闻的核心文本语义。它们都作为后续Prompt模板的输入文本数据。
2.3 提示模板
作为Prompt4NR的核心组件,提示模板 (·)将输入数据(< USER >, < CANDIDATE >)包裹起来,将NR任务转换为cloze-style任务以预测[MASK]。
x_{prompt}=T(< User >,< CANDIDATE >,[MASK]) \\
本文尝试了不同模板的作用。因此,从不同角度设计了三种模板,包括离散、连续和混合模板,以捕捉用户和候选新闻之间匹配信号的不同方式。表1总结了设计的提示模板。

2.3.1 离散模板
离散模板是提示学习中最常见的模板工程类型,它通过可解释的自然语言形式形成输入数据,这需要一些先前的经验性知识。从四个不同的考虑角度设计了四个离散模板,其中每个模板对应一种衡量用户兴趣和候选新闻匹配信号的方法。也就是说,探索哪种[MASK] cloze风格作为相似度测量适用于NR任务。
- 语义相关:检查相关新闻内容是否是用户阅读新闻的核心动机,用户是否对某些特定主题和内容有一种持续的兴趣。将NR任务转化为< CANDIDATE >和< USER >之间的相关性,而答案词选择为“相关”和“不相关”。
- 用户情绪:调查用户对新闻的情感反应是否是最具影响力的因素。用户选择阅读新闻,好像新闻能够大部分满足用户的情感需求。使用“有趣”和“无聊”这两个情感词作为答案来估计用户对< CANDIDATE >的情感反应。
- 用户行为:研究MLM是否可以直接作为点击预测器。兴趣指导行动,行动反映兴趣。输入 < USER >和< CANDIDATE >后,让MLM直接预测用户是否会点击新闻,答案选项为“是”和“否”。
- 推荐效用:探索MLM是否可以自行判断推荐候选新闻的潜在优缺点,即进行这样推荐的效用。向MLM提供一个利用率问题,答案选择为“好”和“坏”作为推荐效用的预测。
2.3.2 连续模板
表1展示了四个连续模板,每个模板对应一个离散模板。在 < USER >、< CANDIDATE > 和 [MASK] 前分别添加了一些虚拟可学习token,表示为[ _1]...[ _{ _1}]、[ _1]...[ _{ _2}] 和 [ _1]...[ _{ _3}],其中 n 是虚拟标记的数量。至于答案词和令牌位置设置,参考离散模板。尽管连续模板为模型提供了更多的自由度,但这些虚拟token的嵌入随机初始化,可能会引入一些歧义,导致 PLM 知识的未充分利用。进一步设计了一种混合模板,试图结合离散和连续模板的优点。
2.3.3 混合模板
在混合模板中,保留了位于 < USER > 和 < CANDIDATE > 前面的那些虚拟标记[ _ ]和[ _ ],自动搜索适当的格式将这些信息呈现给 PLM。使用 [MASK] 令牌代替那些虚拟标记 [ _ ],并用一种自然语言表述作为回答预测所使用的 [MASK] 令牌。如表1所示,设计了四个具有代表性的自然句子。混合模板由一个连续模板、一个 [SEP] 令牌和一个自然句子组成。与连续模板相比,这种混合模板可以通过连续模板的虚拟标记享有更多选择,并由离散模板的自然句子指导答案方向。
2.4 答案预测和表述生成
给定点击历史 _ 和候选新闻 _ ,它们对应一个实际标签 ∈{0,1},反映用户是否点击该候选新闻( =1)或未点击( =0)。我们设计了一个表述生成器 (·),将标签映射为PLM词汇表W中的两个答案单词,具体如下:
v(y)=\left\{\begin{array}{ll} w_{\text {pos }}, & y=1 \\ w_{n e g}, & y=0 \end{array}\right.\\
其中\{w_{pos},w_{neg}\}是答案单词空间,根据使用的提示模板可以不同。NR任务被转换为一种填空式任务,预训练的MLM(例如BERT)预测答案单词作为[MASK]的概率。
P\left(y \mid H_{u}, D_{c}\right)=P_{\mathcal{M}}\left([M A S K]=v(y) \mid x_{\text {prompt }}\right), \\
2.5 训练
采用交叉熵损失函数来训练模型,y_i和P_i分别是第i个训练实例的标签和预测概率。使用AdamW优化器进行模型训练,并使用L2正则化。
\mathcal{L}=-\frac{1}{N} \sum_{i=1}^N\left[y_i \log P_i+\left(1-y_i\right) \log \left(1-P_i\right)\right], \\
3.6 多提示集成
不同模板可能具有不同的优点,因为它们各自关注特定的因素,在PLM中利用语言和语义知识的方式不同。多提示集成将单个提示的预测合并以提高最终决策。由于没有关于哪个模板更好的先验知识,因此只需将每个提示中正向答案单词的概率相加作为最终排名分数。
\hat{y}=\sum_{e\in \mathcal{E}}{P_{e}} \\
P_e是模板e对于w_{pos}的输出概率,\mathcal{E}是模板集合。文中考虑两种多提示集成的方式。一种是融合来自相同类型的模板的预测,其中\mathcal{E}=\{相关性,情感,行为,效用\},离散集成是将四个离散模板的预测结果合并起来。另一种方式是融合不同类型的模板的预测,称为跨类型集成。
3. 结果
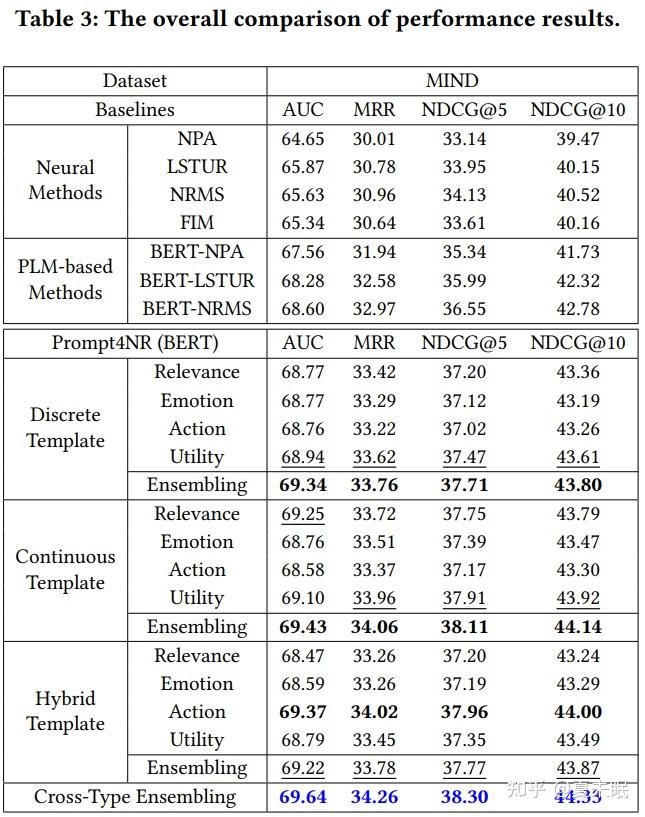
image.png |
|



 发表于 2023-8-4 19:30:32
发表于 2023-8-4 19:30:32