|
|
标题:Learning Implicit Sentiment in Aspect-based Sentiment Analysis with Supervised Contrastive Pre-Training
作者:Zhengyan Li, Yicheng Zou, Chong Zhang, Qi Zhang and Zhongyu Wei
来源:Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing
code:tribleave/scapt-absa
1 Introduction
方面级情感分析 (ABSA) 是一种细粒度的变体,旨在识别产品评论中一个或多个提及方面的情感极性。最近的研究通过使用注意力机制(Wang et al,2016b;Ma et al,2017)或结合语法感知图结构(He et al,2018;Tang et al,2020;Zhang et al., 2019; Sun et al., 2019; Wang et al., 2020)来解决该任务。这两种方法都旨在捕获针对特定方面的相应情感表达,这通常是明确表达情感极性的意见词。
然而,隐式情感表达广泛存在于基于方面的情感识别中。隐式情绪表达表示不包含极性标记但仍能在上下文中传达清晰的人类感知情绪极性的情绪表达 (Russo et al., 2015)。如表1所示,针对“服务员”方面的评论“服务员往我手上倒了水然后走开了”不包含任何意见词,但可以清楚地解释为是否定的。根据表 2(如第 4 节所示),27.47% 和 30.09% 的评论包含餐厅和笔记本电脑数据集中的隐含情绪。然而,大多数先前的方法通常很少关注对隐式情感表达的建模。这促使我们通过以高级方式捕获隐含情绪来更好地解决 ABSA 的任务。

为了使当前模型具备捕捉隐含情绪的能力,不充分的 ABSA 数据集是主要挑战。只有几千个标记数据,模型很难识别情感表达的全面模式,也无法捕获情感识别所需的足够的常识知识。它揭示了应该引入外部情感知识来解决问题。
因此,我们在外部大规模情感注释语料库上采用监督对比预训练(SCAPT)来学习情感知识。监督对比学习给出了具有相同情感标签的情感表达的对齐表示。在嵌入空间中,具有相同情感方向的显式和隐式情感表达被拉到一起,而具有不同情感标签的情感表达被推开。考虑到检索到的语料库的情感注释是嘈杂的,有监督的对比学习增强了预训练过程的抗噪性。此外,SCAPT 包含审查重建和掩蔽方面预测目标。前者除了情感极性外还需要对评论上下文进行表示编码,后者增加了模型捕获情感目标的能力。总体而言,预训练过程捕获了对评论方面的隐式和显式情绪导向。
在 SemEval-2014 (Pontiki et al., 2014) 和 MAMS (Jiang et al., 2019) 数据集上进行的实验评估表明,提出的 SCAPT 大大优于基线模型。分区数据集的结果证明了隐式情感表达和显式情感表达的有效性。此外,消融研究验证了 SCAPT 有效地学习了外部嘈杂语料库上的隐含情感表达。
这项工作的贡献包括:
• 我们揭示了 ABSA 仅被先前的研究略微解决,因为他们很少关注内隐情绪。
• 我们提出监督对比预训练来从大规模情感注释语料库中学习情感知识。
• 实验结果表明,我们提出的模型实现了最先进的性能,并且可以有效地学习隐含情绪。
2 Implicit Sentiment
作为只能在评论的上下文中推断的情感,许多研究解决了情感分析中隐含情感的存在。Toprak et al.(2010);Russo et al.(2015) 提出了类似的术语(如隐含极性或极性事实),并提供了包含隐含情感的语料库。 Deng 和 Wiebe (2014) 通过对显式情绪表达和所谓的事件的推断来检测隐式情绪。 Choi 和 Wiebe (2014) 使用 +/-EffectWordNet 词典来识别隐含情绪,假设情绪表达通常与对实体有正面/负面/空影响的状态和事件相关。
为了调查 ABSA 中无处不在的隐式情绪,我们根据意见词的存在将 SemEval-2014 餐厅和笔记本电脑基准分为显式情绪表达 (ESE) 切片和隐式情绪表达 (ISE) 切片。Fan et al.(2019)在 SemEval 基准上为目标方面注释了意见词。我们注意到提供的数据集没有保持原始顺序并且在文本上有一些差异。因此,我们首先将注释与原始数据集进行匹配,然后从剩余部分手动选择评论,包括对方面的意见词。如表 2 所示(见第 4 节),27.47% 和 30.09% 的评论分为餐厅和笔记本电脑中的 ISE 部分,表明隐性情绪在 ABSA 中广泛存在,值得探索。
3 Methodology
在本节中,我们介绍了我们模型的预训练和微调方案。在预训练中,我们为 ABSA 引入了监督对比预训练(SCAPT),它通过利用检索到的评论语料库来学习情感表达的极性。在微调中,采用aspect-aware微调来增强模型在基于aspect的情感识别方面的能力。
3.1 Supervised Contrastive Pre-training
SCAPT 中包含三个目标:监督对比学习、掩蔽方面预测和评论重建。 SCAPT 的详细信息如图 1 所示。
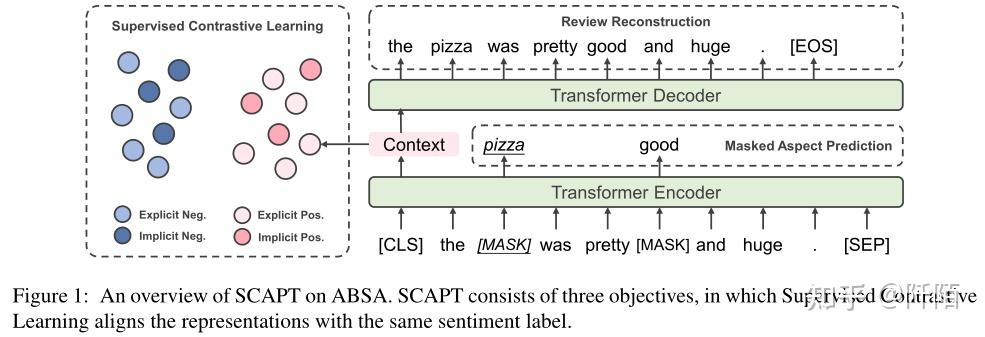
Transformer Encoder Backbone 预训练方案基于 Transformer 编码器(Vaswani et al,2017)。我们将 SCAPT 中使用的检索到的评论语料库表示为 D = {x1, x2, . . . , xn} 。第 i 个句子 xi 用 yi 标记。对于每个输入句子 xi,遵循 Devlin et al. (2019),我们将输入句子格式化为 Ii = [CLS] + xi + [SEP] 。 [CLS] token 的输出向量对句子表示 ¯hi 进行编码:
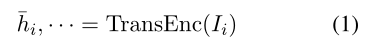
Supervised Contrastive Learning:受 Khosla et al.(2020)的启发,我们在 SCAPT 中采用监督对比学习目标,将显式和隐式情绪表达的表示与相同的情绪对齐。监督对比学习鼓励模型在上下文中捕捉隐含的情感方向并将其合并到情感表示中。
具体来说,对于batch B 中的 (xi, yi),我们首先从 xi 的句子表示 ¯hi 中提取情感表示 si = Ws¯hi。 Ws 可以被看作是一个可训练的句子情感感知器。batch B 的监督对比损失定义为:
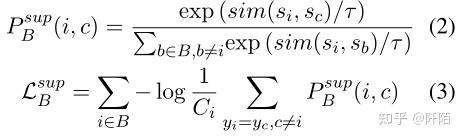
这里,P sup B (i, c) 表示 sc 与 si 最相似的可能性,τ 是 softmax 的程度。这里我们简单地使用 sim(si, sc) = si · sc 作为相似度度量。监督对比损失 Lsup B 对 B 中的每个句子 si 计算,其中 Ci 是 B 中相同类别 yi 的样本数。值得注意的是,我们在监督对比预训练过程中不直接使用句子表示。相反,我们使用情感表示来充分利用文档级标记的语料库来挖掘固有的情感感知。
Review Reconstruction:受去噪自动编码器(Vincent et al,2008)及其在预训练模型中的成功(Lewis et al,2020 )的启发,我们进一步提出了评论重建任务,以增强上下文语义建模的句子表示。仅对仅关注情绪正则化的监督对比学习任务进行预训练,基本语义信息并未完全保留在句子表示中。因此,我们另外在 SCAPT 中使用评论重建来捕获句子表示中的综合上下文信息。
一般来说,这个目标用句子表示 ¯hi 重构整个句子 xi。在将 xi 编码为句子表示 ¯hi 后,后者被馈送到 Transformer 解码器进行自回归生成:
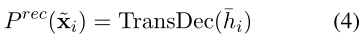
〜xi 是恢复的句子。 ¯hi 在解码过程中充当句首输入嵌入,以控制整个生成过程。我们使用没有掩码的原始句子 xi 作为评论重建目标的黄金参考:
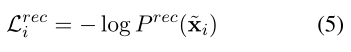
Masked Aspect Prediction:在掩蔽方面预测中,模型学习从每个评论的损坏版本中预测掩蔽方面。输入评论的屏蔽策略包括以下两个步骤:
1. Aspect Span Masking。由于所有输入都来自我们检索到的语料库,因此我们确保每条评论至少包含一个方面。对于每个输入,aspect spans的token以80%的概率替换为[MASK],或者以10%的概率替换为随机token,否则保持不变。方面跨度掩蔽提供了更好地捕获方面词。
2. 随机掩蔽。在aspect span masking之后,如果被掩码的token的比例小于15%,我们会随机从其余token中屏蔽掉多余的token以达到这个比例。
我们将 [MASK] 的输入标记表示为 wMASK。对于第 k 个位置的每个掩码输入标记,其上下文化隐藏表示 hik 被输入到 softmax 层以预测原始单词:
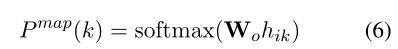
具体到上式,hik是Transformer encoder在第k个位置的输出,Wo是一个可训练的参数矩阵,P map(k) 表示原词在第k个位置的预测概率。掩蔽方面预测损失是对每个掩蔽位置预测的对数似然的累积:
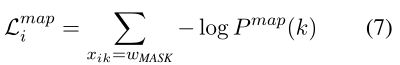
与 MLM (Devlin et al., 2019) 或情感掩蔽 (Tian et al., 2020) 不同,掩蔽方面预测更侧重于在基于方面的表示中对方面相关的上下文信息进行建模,这与其他预训练目标相辅相成,对我们的微调方案有利。
Joint Training:上面提到的三个损失在 SCAP 中结合起来联合训练。对于batch B上的整体预训练损失Lpre B,在每个示例b∈B上计算review重建损失和方面遮挡预测损失,α和β是平衡目标的系数:
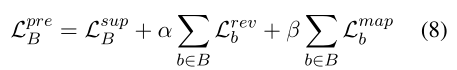
3.2 Aspect-Aware Fine-tuning
我们提出的模型通过方面感知微调在ABSA基准上进行微调,以充分利用它们的情感识别能力。他们还学习在微调期间捕获与方面相关的情绪信息。
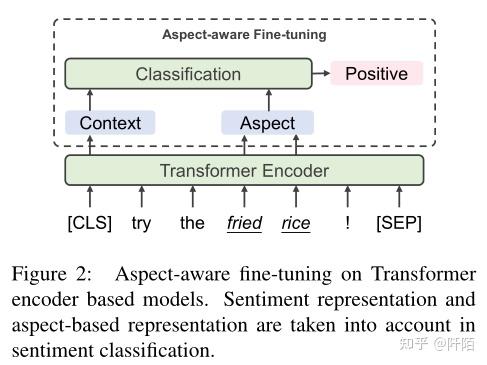
具体来说,给定一个句子 xab = {w1, . . . , 哇, . . . wn} ,wa 是 xab 中出现的方面之一。在微调中,模型根据基于方面的表示 ¯haba 和情感表示 sab 预测方面级别的情感方向 yaba。
Aspect-based Representation 关于预训练的上下文化单词表示的研究 (Ethayarajh, 2019) 表明它可以捕获与单词相关的上下文信息。因此,尽管使用了费力的方法来嵌入方面信息,我们还是通过收集对应于 wa 的最终隐藏状态来提取基于方面的表示 haba。在微调中,haba 将专注于上下文中与方面相关的词,我们认为这将增强对特定于方面的意见词的感知,并使模型对明确的情感有很好的看法。具体来说,让 Ia 是方面 xa 中的标记索引,我们平均所有 i ∈ Ia 的隐藏状态 hi 以获得基于方面的表示:
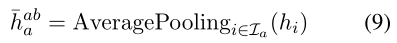
值得注意的是,在处理在句子 xab 中多个方面时,wa1,wa2,. . .,我们提取基于方面的表示 ¯haba1, ¯haba2 . ..在一次运行中,先前的方法为每个方面一个接一个地嵌入方面和编码器的整个输入。
Representation Combination 对于情感分类,基于方面的表示和情感表示被联合考虑来预测方面级别的情感极性。在这种情况下,微调模型建立了对单词出现相关的显式情感和语义相关的隐式情感的感知。我们在预训练中使用相同的情感感知器 Ws 从句子表示中提取情感表示 sab。然后将情感表示 sab 和基于方面的表示 ¯haba 连接起来以预测方面级别的情感极性:
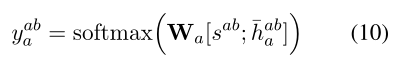
yaba 是关于方面 xa 的预测,Wa 是可训练的参数矩阵。最后,我们的微调目标是预测任务 Lab = - P xab∈Dab log yaba 的交叉熵损失。
4 Experimental Settings
ABSA Datasets
SemEval 2014 任务 4 (Pontiki et al., 2014) 的Laptop and Restaurant review 这两个基准上进行。我们使用其测试部分的 ESE 和 ISE 切片来分别评估模型在显式和隐式情感上的性能。第 2 节详细介绍了构建这些切片的过程。此外,我们还使用了更具挑战性的数据集 Multi-Aspect Multi-Sentiment (MAMS) (Jiang et al., 2019),它与 SemEval2014 Restaurant 共享相同的域。所有这些数据集都涉及三个情绪类别,即积极、中性和消极。
Retrieved External Corpora 我们从文档级标记数据中检索大规模情感注释语料库进行预训练。具体来说,我们首先从 Yelp和 Amazon Review (He and McAuley, 2016) 数据集中提取五星级/一星级评论,并将它们标记为正面/负面。这样的过程可以减轻 5级评级的文档级情感语言源中的噪声。然后,我们保留餐厅/笔记本电脑主题中的评论,以确保预训练语料库和 ABSA 数据集在同一个域中。稍后,我们将这些文档级评论拆分为句子,并保留包含与 ABSA 训练集中提到的相同方面术语的句子。每个句子的情感标签由其原始评论的标签决定。在检索过程之后,我们最终从 Yelp/Amazon 获得了大约 1.56/0.51 百万条句子级评论,这些评论被标记为正面/负面。在手动检查两个语料库的一小部分后,我们确认隐式和显式情感表达都可用。我们在检索到的与下游 ABSA 任务共享相同域的语料库上预训练我们的模型。具体来说,我们在处理 Restaurant 或 MAMS 时采用 Yelp,而对于笔记本电脑,我们采用 Amazon。
Models with SCAPT 我们将 SCAPT 应用于 Transformer 编码器和 BERT,这些模型通过 aspect-aware 微调进行微调。这些模型分别是所谓的 TransEncAsp+SCAPT 和 BERTAsp+SCAPT。我们使用一个 300 维随机初始化的 Transformer 编码器,它有 6 层和 6 个头,并且 BERTbase-uncased 作为基础。 Transformer 编码器和 BERT 的预训练分别需要 80 和 8 个 epoch。我们采用 Adam (Kingma and Ba, 2015) 和预热来优化我们的模型,Transformer 编码器的学习率为 1e-3,BERT 的学习率为 5e-5。预训练模型通过 5e-5 学习率的方面感知微调进行微调。超参数设置为 α = β = 1 用于在 SCAPT 中组合目标,而 τ = 0.07 在监督对比学习中。
5 Results and Analysis
本节主要展示实验结果。我们的模型在三个 ABSA 基准上达到了最先进的水平,我们从多个角度说明了监督对比学习的表示对齐效果和其他部分的有效性。此外,我们揭示了我们的模型能够识别隐含情绪,并将其有效性归因于 SCAPT 中的监督对比学习。
5.1 Main Results
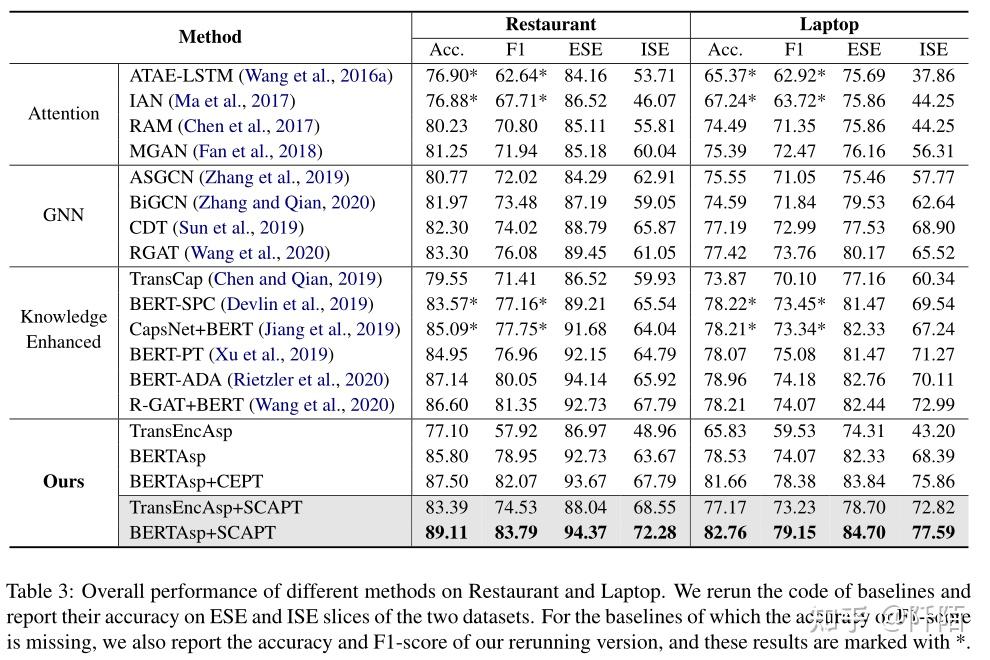
基线和我们提出的模型的性能如表 3 所示。模型使用 Accuracy 和 Macro-F1 进行评估。根据结果,可以注意到几个观察结果。
Our model achieves SOTA performance.ERTAsp+SCAPT 在餐厅/笔记本电脑上的表现优于当前的 SOTA 模型 1.97%/3.80%。 TransEncAsp+SCAPT 在没有预训练知识的情况下比大多数基线表现更好。此外,BERTAsp+SCAPT 在两个数据集的 ESE/ISE 切片上也取得了最佳性能,揭示了所提出的预训练方案的有效性。
After pre-trained with SCAPT, models improve significantly on ABSA tasks.与直接在 ABSA 数据集上微调的 BERTAsp 相比,BERTAsp+SCAPT 在餐厅/笔记本电脑上实现了 3.31%/4.23% 的性能提升,这有力地证明了通过适当的自适应预训练获取领域内知识对于知识仍然是必要的——增强模型,而 SCAPT 是一种有效的方法。此外,TransEncAsp+SCAPT 比 TransEncAsp 好 6.29%/11.34%,说明将情感知识与 SCAPT 相结合极大地增强了 ABSA 模型。
SCAPT is good at learning implicit sentiment.这可以从几个方面来验证。首先,与它在 ESE 上的表现相比,BERTAsp+SCAPT 在 ISE 上似乎要好得多。与其他工作相比时,BERTAsp+SCAPT 在 ESE 切片上提高了 0-2% 左右,但在 ISE 切片上超过了之前的 SOTA 模型 4.49%/4.60%。因此,BERTAsp+SCAPT 的良好表现主要有助于其对内隐情绪的认识。其次,TransEncAsp+SCAPT 在 ISE 切片上的表现比 BERTAsp 好得多。 TransEncAsp+SCAPT 仅暴露于百万级预训练语料,在整个任务上普遍比 BERTAsp 差,但在 ISE 切片上超过 BERTAsp 4.88%/4.43%。这表明 SCAP 在学习隐含情绪方面是数据有效的。最后,在使用 SCAPT 进行预训练后,模型在 ISE 上获得了显着的性能提升,这比 ESE 要重要得多。 BERTAsp+SCAPT 在 ESE 上比 BERTAsp 好 2%,但在 ISE 上优于后者 8.61%/9.20%。对于基于 Transformer 编码器的模型,在 SCAP 之后 ISE 的性能提升超过 20%。我们得出结论,模型在 SCAPT 中学到的主要是对隐含情绪的感知。
Aspect-aware fine-tuning serves as a complement to SCAPT. 我们发现具有切面感知微调的模型在数据集的 ESE 切片上表现更好。具体来说,与 BERT-SPC 相比,BERTAsp 在 ISE 上的表现更差,但在 ESE 上的表现更好,因此在两个数据集上被评估为更好。 BERTAsp 在 ESE 切片上的更好性能可能主要是由于它使用了基于方面的表示,它关注可能包含情感方向的方面相关的上下文。方面感知微调的这一特性使其适用于增强对使用 SCAPT 预训练的模型的显式情感的识别。
5.2 Effectiveness on Multi-aspect ABSA
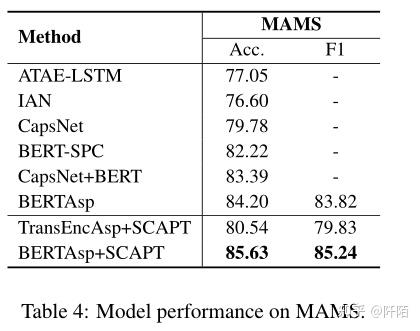
表 4 显示了基线和我们的模型在 MAMS 数据集中的性能。尽管在单个句子中区分多个方面的情感极性具有挑战性,但结果表明 TransEncAsp+SCAPT 优于缺乏外部情感知识的基线,而 BERTAsp+SCAPT 在多方面场景中实现了最先进的水平。我们模型的效率可以归因于 SCAPT 和方面感知微调,因为它们分别增强了对隐式和显式情绪的学习。此外,与餐厅/笔记本电脑相比,BERTAsp 在 MAMS 中的性能比 BERTSPC 好得多。我们认为 BERTAsp 的出色表现归功于其在基于方面的表示中对上下文信息的建模,这在多方面 ABSA 中更为重要。
5.3 Implicit Sentiment Learning in SCAPT
我们将 SCAPT 中隐式情感学习的关键方面总结为暴露情感知识和使用监督对比学习。表 3 中的结果表明,隐式情绪比显式情绪更难学习,而以前基于注意力或句法建模的方法并不能完美地解决这个问题。知识增强的基线在 ISE 上的性能提高了 5%,性能略好一些。通过对大规模情感注释语料库进行预训练,我们的模型在隐式情感学习方面取得了显着的性能提升,在 TransEncAsp 上的相对增益为 19.59%/29.62%。这些结果证明,域内情感知识对于隐式情感学习是绝对必要的,这是由我们检索的语料库提供的。此外,使用监督对比学习目标进行预训练的模型在ISE 切片。与 BERTAsp+CEPT 相比,BERTAsp+SCAPT 在 ISE 上的性能提升了 4.49%/1.73%,这导致其在整个任务上的性能更好。监督对比学习目标的部署增强了预训练过程的抗噪性,因此预训练模型在学习隐含情感方面更有效。
5.4 Ablation Study on SCAPT
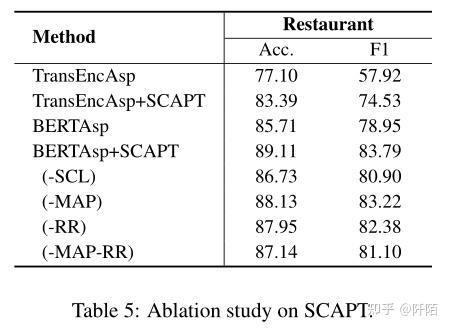
如表 5 所示,我们通过消融研究验证了每个部分的有效性。首先,去除监督对比学习损失 (-SCL) 会导致 Restaurant 的性能下降 2.38%,这比去除其他两个目标 (-MAP-RR) 的情况更为显着。这验证了有监督的对比学习在 SCAPT 中起主要作用。此外,我们观察到去除掩蔽方面预测和审查重建目标也会导致性能下降。这表明这些机制在 SCAP 中也是不可或缺的。
5.5 Hidden Sentiment Representations
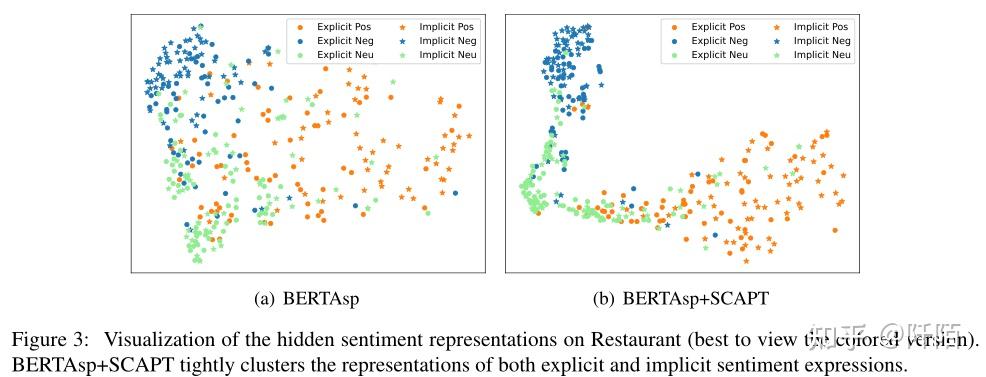
为了更好地理解我们提出的方法的行为,我们进一步使用 t-SNE 对情感表示进行可视化(Van der Maaten 和 Hinton,2008)。如图 3 所示,带有情感预训练的模型对情感表达具有很强的嵌入能力,而在 BERTAsp 中可以发现许多错误分类。可视化还显示 BERTAsp+SCAPT 将隐式和显式情绪表达的表示紧密聚类。
5.6 Aspect Robustness
我们分析了我们提出的模型在方面鲁棒性测试集上的鲁棒性。 Xing 等人首先强调并测试了 ABSA 方面的稳健性。 (2020 年)通过对餐厅和笔记本电脑的评论应用若干扰动。 TextFlint (Wang et al., 2021) 通过从各种语言角度引入转换来扩展这些转换。测试集旨在探索模型是否可以将目标方面的情绪与非目标方面和无关信息区分开来。
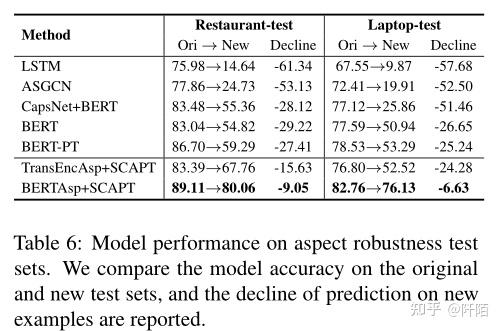
表 6 列出了测试模型的性能,其中我们提出的模型的鲁棒性得到了令人信服的证明。与基线模型的明显性能下降相比,BERTAsp+SCAPT 在餐厅和笔记本电脑上的性能明显优于其他模型,分别下降了 9.05%/6.63%。结果表明,使用 SCAPT 预训练的模型对于方面级别的扰动更加稳健,这归因于通过增强域内情感知识对情感和上下文信息进行更好的建模。
6 Related Work
Neural Network Methods for ABSA。ABSA 中的早期神经网络方法(Wang et al,2016b;Ma et al,2017)采用各种注意机制来识别与方面相关的上下文。记忆网络(Tang et al., 2016; Chen et al., 2017; Wang et al., 2018)被进一步提出来识别aspect的相应情感表达。最近的工作(He et al,2018 ;Tang et al,2020)使用依赖树中的语法信息来增强基于注意力的模型。很多工作(Zhang et al., 2019; Sun et al., 2019; Wang et al., 2020)利用图神经网络来整合树形结构的句法信息并在文本中捕获与方面相关的信息。 ABSA 中的另一条线专注于利用外部语料库和预训练知识来增强模型的语义意识(Xu et al,2019;Rietzler et al,2020;Dai et al,2021)。
Contrastive Representation Learning。我们的工作在表示学习中采用对比方法来获取有区别的实例表示。最近关于实例对比表示学习的工作通常基于估计相似和不相似对的表示相似性,这些对通常以自我监督的方式组成(Chen et al., 2020; He et al., 2020)。特别是,Khosla et al (2020) 说明了一种监督对比方法,用于在具有相同类标签的实例之间建立正对,并将它们的表示放在一起。在这项工作中,我们的模型在有监督的对比预训练中学习从信息丰富但嘈杂的语言资源中捕捉隐含情绪。
7 Conclusion
在本文中,我们介绍了 ABSA 的监督对比预训练 (SCAPT)。通过注意到当前基于神经网络的 ABSA 模型不能很好地处理隐式情绪,我们认为需要更多的情绪知识来解决这个问题。因此,我们检索大规模的域内注释语料库,并提出 SCAPT 从语料库中学习情感知识。实验结果表明,我们提出的具有 SCAPT 的模型实现了 SOTA 性能。此外,SCAP 被证明在隐式情感学习中是有效的。我们希望通过知识增强方法启发未来关于学习和建模隐性情感的研究。 |
|



 发表于 2022-9-22 15:59:57
发表于 2022-9-22 15:59:57