|
|
作者|Kevin C Lee
编译|VK
来源|Towards Data Science
原文链接:https://towardsdatascience.com/sentiment-analysis-comparing-3-common-approaches-naive-bayes-lstm-and-vader-ab561f834f89 注意:这个帖子的代码可以在这里找到:https://github.com/kevinclee26/sentiment_analysis_classification
情感分析,或观点挖掘,是自然语言处理(NLP)的一个子领域,旨在从文本中提取态度、评价、观点和情感。
受客户的互动迁移到数字格式(如电子邮件、聊天室、社交媒体帖子、评论和调查)的启发,情感分析已成为分析组织必须执行的一个组成部分,以了解其在市场中的定位。
明确地说,情感分析不是一个新颖的概念。事实上,它一直是CRM(客户关系管理)和市场研究的重要组成部分——公司依靠更好地了解客户来发展和创新。
最近的增长主要是由于客户交互记录的可用性/可访问性以及处理这些数据的计算能力的提高。这一进步确实让消费者受益匪浅。
各组织比以往任何时候都更愿意听取选民的意见以改进。情感分析有很多方法。在本文中,我们将探讨三种方法:
1)朴素贝叶斯
2)深度学习LSTM,
3)预训练的基于规则的VADER模型。
我们将重点比较简单的开箱即用模型,并认识到每种方法都可以调整以提高性能。我们的目的不是详细介绍每种方法的工作原理,而是对它们如何进行比较进行概念性研究,以帮助确定何时应该选择一种方法而不是另一种方法。
情感分析的背景
情感分析的目标范围从积极到消极。与其他NLP工作一样,它通常被认为是一个分类问题,尽管当精度很重要时,它可以被视为一个回归问题。
情感分析过去是由大量劳动力阅读和手动评估文本来完成的。这种方法成本高昂,而且容易出现人为错误。为了使这一过程自动化,公司寻求先进的分析方法来解决这一问题。
情感分析的挑战在于人们表达和解释情绪的极性和强度不同。此外,单词和句子可以根据上下文有多种含义(称为多义)。虽然其中一些问题可以缓解,但与任何分析任务一样,速度和性能之间几乎总是存在权衡。
我们回顾了三种通用方法,每种方法各有优缺点:

介绍数据集
除了强调概念上的差异外,我们还使用数据集对性能进行基准测试。该数据集包含160万条推特和相应的情绪标签(正面和负面)。
原始数据:
VADER词典和基于规则的情感分析工具
我们首先使用流行的VADER(Valence-Aware Dictionary and Threaction Reasoner)工具,采用一种易于应用的方法。
VADER的核心是使用全面、高质量的词汇(约7500个特征)和复杂的语言规则来生成情感分数。情感词典的构建和验证(统计)在其发表的论文中有详细的记录——这一巨大的成就怎么强调都不为过。
// vader_lexicon.txt
...
good: 1.9
happy 2.7
awesome 3.1
bad -2.5
sad -2.1
catastrophic -2.2
...
正如上面的示例所示,VADER是一个为每个特征(可以是单词、首字母缩略词或表情符号)指定-4(最极端负面)到4(最极端正面)之间预先确定的情感分数的词典。
VADER能够检测情感的强度和极性方面,并与强大的修饰语(如否定、收缩、连词、加强词、程度副词、大写、标点和俚语)相结合,用于计算输入文本的分数。
这些修饰符作为基于规则的模型来实现。VADER的开发人员使其开源且易于使用:
# 导入SentimentIntensityAnalyzer
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
# polarity_scores方法
SentimentIntensityAnalyzer().polarity_scores('Today is a good day.')
# output:
# {'neg': 0.0, 'neu': 0.58, 'pos': 0.42, 'compound': 0.4404}
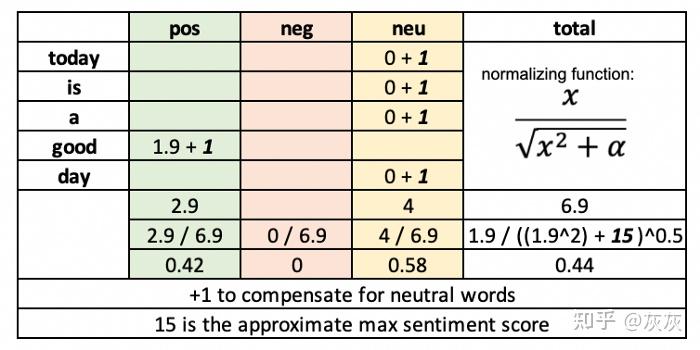
VADER生成一个复合分数,总结输入文本的情绪强度。通过将词典中每个特征的分数相加,根据规则进行调整,然后标准化为-1(最极端的负)和+1(最极端的正)之间。
文件将复合分数描述为“标准化加权综合分数”。此外,pos、neg、neu分数代表属于每个类别的文本比例
import pandas as pd
from sklearn.metrics import accuracy_score
# 读取分数
df=pd.read_csv('data/sample.csv')
# 使用Vader计算分数
def get_vader_score(sentence):
compound=analyzer.polarity_scores(sentence)['compound']
if compound > 0.05:
return 1
elif (compound >= -0.05) and (compound <=0.05):
return None
else:
return 0
df[&#39;vader&#39;]=df.apply(lambda x: get_vader_score(x[&#39;text&#39;]), axis=1)
# 评估结果
print(f&#39;Accuracy: {accuracy_score(df.dropna()[&#34;label&#34;].values, df.dropna()[&#34;vader&#34;].values)}&#39;)
基于规则的模型易于理解和快速实现,是情感分析的一个有吸引力的选择。
它们取决于拥有强大的词汇和全面的语言规则。基于规则的模型面临的挑战是词典的创建和验证非常耗时。他们在无休止的词汇特征组合中挣扎,这些词汇特征可能很重要,当单词有不同的含义时,他们也会在不同的领域中挣扎。
此外,该方法只评估单个单词,而忽略了使用它们的上下文。这通常会导致错误,尤其是讽刺文本。
使用VADER-我们能够在测试数据集上得出72%的准确分数。
VADER考虑了社交媒体文本中常见的表情符号和首字母缩略词/首字母缩略词,因此它可以在该领域中表现,但在其他领域中表现可能更差。
重要的是要注意,VADER确实产生了精确的极性分数,为了便于比较,我们将其归类为正或负。
自然语言处理中的机器学习
虽然基于规则的解决方案已经被证明是性能和可靠的,但它是刚性的,并且受到可能过期的词典的限制。
手动创建和验证一个全面的情感词典是困难的。相反,我们希望转向一种机器学习解决方案,通过算法将输入文本与相应的标记相关联。
在训练过程中,将成对的文本和标记(情感)输入机器学习算法,以创建能够对新文本进行预测的模型。值得一提的一个重要警告是,有监督的机器学习要求对数据进行标记,这可能意味着数据中的任何主观性和偏见都会反映在模型中。
与预先训练的模型相比,自定义模型可以更好地控制输出,并且适用于特定的应用程序。
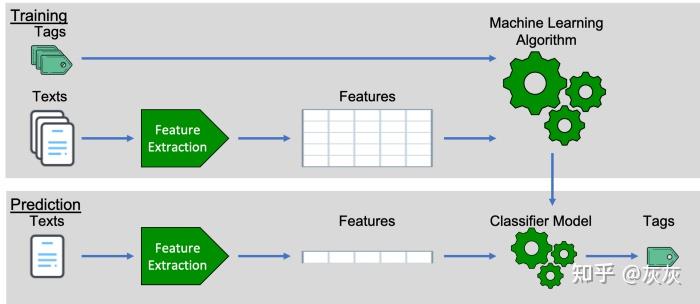
机器学习NLP文本分类过程:
朴素贝叶斯
朴素贝叶斯分类器使用概率根据可能相关条件的先验知识进行预测。换句话说,它使用训练数据中出现在正文本或负文本中的每个词汇特征的条件概率来得出结果。
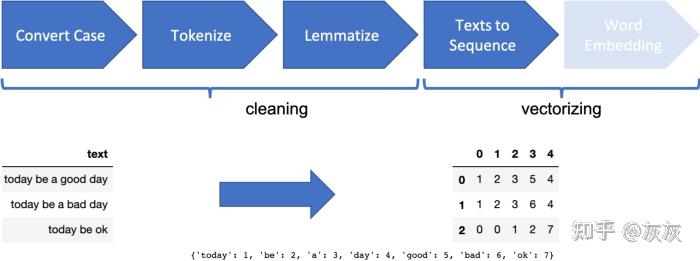
NLP的机器学习需要预处理以从原始文本中提取特征。
具体而言,它需要将文本数据转换为数字表示,然后算法才能处理它们,即矢量化。
对于Naive Bayes,我们将构建一个简单的DTM(文档词频矩阵)用于模型使用,尽管可以包括其他特征,如文本长度、发布时间/位置、命名实体等。
DTM往往会产生一个广阔的特征空间,因为整个语料库词汇表中的每个唯一单词或短语都成为一个特征。
我们包括一些数据清理步骤,以帮助降低维度和提高模型(分类器)性能。
有关NLP数据预处理的更多信息,请参见此处。
https://towardsdatascience.com/what-you-need-to-know-about-data-preprocessing-and-linguistic-annotations-for-natural-language-439d42f2f355
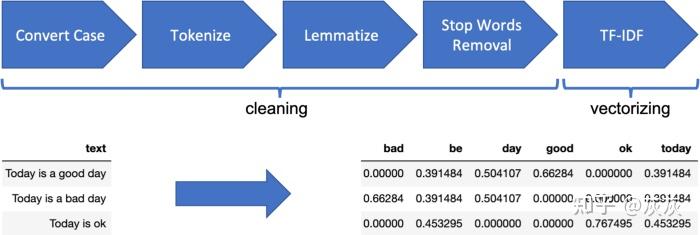
向量表示是通过计算TF(词频)并使用IDF(逆文档频率)对其进行加权来构建的。我们可以使用N-gram来捕获文本中的一些上下文。N-gram上下文是一种迟钝的工具,不能总是正确地捕获表达式。它们也会给模型增加太多的特征,从而对模型产生负面影响。
我们应用以下转换来生成训练/测试数据:
朴素贝叶斯数据预处理管道(加权频率计数)
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import FunctionTransformer
from sklearn.model_selection import train_test_split
# 多项式朴素贝叶斯
# 连续高斯分布
from sklearn.naive_bayes import MultinomialNB, GaussianNB
from sklearn.pipeline import Pipeline
from nltk.stem import WordNetLemmatizer
from nltk.tokenize import TweetTokenizer
from nltk.corpus import stopwords
from nltk.tag import pos_tag
import pandas as pd
# 读入数据
df=pd.read_csv(&#39;data/sample.csv&#39;)
# 创建并运行数据处理管道
def data_cleaning(text_list):
stopwords_rem=False
stopwords_en=stopwords.words(&#39;english&#39;)
lemmatizer=WordNetLemmatizer()
tokenizer=TweetTokenizer()
reconstructed_list=[]
for each_text in text_list:
lemmatized_tokens=[]
tokens=tokenizer.tokenize(each_text.lower())
pos_tags=pos_tag(tokens)
for each_token, tag in pos_tags:
if tag.startswith(&#39;NN&#39;):
pos=&#39;n&#39;
elif tag.startswith(&#39;VB&#39;):
pos=&#39;v&#39;
else:
pos=&#39;a&#39;
lemmatized_token=lemmatizer.lemmatize(each_token, pos)
if stopwords_rem: # False
if lemmatized_token not in stopwords_en:
lemmatized_tokens.append(lemmatized_token)
else:
lemmatized_tokens.append(lemmatized_token)
reconstructed_list.append(&#39; &#39;.join(lemmatized_tokens))
return reconstructed_list
estimators=[(&#39;cleaner&#39;, FunctionTransformer(data_cleaning)),
(&#39;vectorizer&#39;, TfidfVectorizer(max_features=100000, ngram_range=(1, 2)))]
preprocessing_pipeline=Pipeline(estimators)
# 将数据分解为训练集和测试集
X=df[&#39;text&#39;]
y=df[&#39;label&#39;]
X_train, X_test, y_train, y_test=train_test_split(X, y)
# 对管道进行拟合和变换
X_train_transformed=preprocessing_pipeline.fit_transform(X_train)
# 创建朴素贝叶斯模型并拟合训练数据
nb=MultinomialNB()
nb.fit(X_train_transformed, y_train)
X_test_transformed=preprocessing_pipeline.transform(X_test)
# 评价模型
print(f&#39;Test Score: {nb.score(X_test_transformed, y_test)}&#39;)
print(f&#39;Test Score: {nb.score(X_train_transformed, y_train)}&#39;)
朴素贝叶斯模型使用了相当容易理解的特征。它支持大规模情感分析工作,因为训练所需的计算速度很快。
然而,它确实有一些明显的缺点。作为一种概率分类器,它高度依赖先验知识,因此训练数据必须完整且具有代表性。
缺乏良好的训练数据会导致对看不见的数据或词汇量不足的文本的推理能力差。如果数据中存在偏差或不平衡,它也会受到影响。
此外,它假设特征是相互独立的,这意味着DTM中的词汇特征在所有句子中的贡献是相等的,而与文本中的相对位置无关。朴素的Bayes DTM模型(具有300K unigram和bigram特征)训练速度快(<7分钟)。训练分数的准确率为86%,测试/验证分数的准确率为79%。
对于更长更宽的数据集,可以使用Spark使用此处的代码快速训练模型:https://gist.github.com/kevinclee26/95ef550f53df7d6fae6c332425367028。
深度学习
深度学习允许以更复杂的方式处理数据。长短期记忆模型(LSTM)是一种用于处理时态数据的递归神经网络(RNN)。
深度学习的计算成本很高,而且对于高维稀疏向量来说效果不佳(性能差,收敛速度慢)。当我们从原始文本中提取特征进行模型训练时,我们需要将它们表示为密集的向量。
其中一种技术是将每个文本转换为数字序列,其中每个数字都映射到词汇表中的一个单词。更进一步,我们需要使用词嵌入将具有类似用法/含义的单词映射到类似的实数向量(而不是索引)。
如果没有词嵌入,该模型会将单词的索引号误解为有意义。词嵌入将所有单词放入多维向量空间,因此它们的相似性可以通过距离来衡量。
使用开源预训练模型(如Word2vec、GloVe或fastText)或自定义神经网络(无监督学习)模型生成词嵌入。
在训练自定义词嵌入时,可以单独进行,也可以与手头任务的神经网络模型(作为附加层)联合进行。
这是我们所采用的方法,因为它往往会导致针对数据上下文和目标的嵌入。与稀疏(几十万维)的文档术语矩阵不同,使用词嵌入生成的向量在捕获语义相似性的同时具有更少(数百)维。词嵌入被认为是深度学习在解决自然语言处理难题方面的关键突破之一。
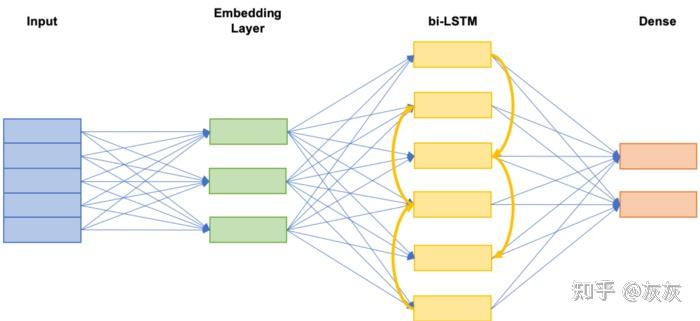
我们应用以下转换来生成训练/测试数据:
词嵌入+LSTM数据预处理流水线
词嵌入LSTM体系结构
import pandas as pd
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categorical
from nltk.stem import WordNetLemmatizer
from nltk.tokenize import TweetTokenizer
from nltk.corpus import stopwords
from nltk.tag import pos_tag
from sklearn.model_selection import train_test_split
from keras.models import Sequential
from keras import layers
# 读入数据
df=pd.read_csv(&#39;data/sample.csv&#39;)
# 创建数据集的所有特征
def data_cleaning(text_list):
stopwords_rem=False
stopwords_en=stopwords.words(&#39;english&#39;)
lemmatizer=WordNetLemmatizer()
tokenizer=TweetTokenizer()
reconstructed_list=[]
for each_text in text_list:
lemmatized_tokens=[]
tokens=tokenizer.tokenize(each_text.lower())
pos_tags=pos_tag(tokens)
for each_token, tag in pos_tags:
if tag.startswith(&#39;NN&#39;):
pos=&#39;n&#39;
elif tag.startswith(&#39;VB&#39;):
pos=&#39;v&#39;
else:
pos=&#39;a&#39;
lemmatized_token=lemmatizer.lemmatize(each_token, pos)
if stopwords_rem: # False
if lemmatized_token not in stopwords_en:
lemmatized_tokens.append(lemmatized_token)
else:
lemmatized_tokens.append(lemmatized_token)
reconstructed_list.append(&#39; &#39;.join(lemmatized_tokens))
return reconstructed_list
# 将数据分解为训练集和测试集
X=df[&#39;text&#39;]
y=df[&#39;label&#39;]
X_train, X_test, y_train, y_test=train_test_split(X, y)
# 拟合并转换数据
X_train=data_cleaning(X_train)
X_test=data_cleaning(X_test)
tokenizer=Tokenizer()
tokenizer.fit_on_texts(X_train)
vocab_size=len(tokenizer.word_index)+1
print(f&#39;Vocab Size: {vocab_size}&#39;)
X_train=pad_sequences(tokenizer.texts_to_sequences(X_train), maxlen=40)
X_test=pad_sequences(tokenizer.texts_to_sequences(X_test), maxlen=40)
y_train=to_categorical(y_train)
y_test=to_categorical(y_test)
# 创建带有嵌入层的LSTM模型并拟合训练数据
model=Sequential()
model.add(layers.Embedding(input_dim=vocab_size,\
output_dim=100,\
input_length=40))
model.add(layers.Bidirectional(layers.LSTM(128)))
model.add(layers.Dense(2,activation=&#39;softmax&#39;))
model.compile(optimizer=&#39;adam&#39;,\
loss=&#39;categorical_crossentropy&#39;,\
metrics=[&#39;accuracy&#39;])
model.fit(X_train,\
y_train,\
batch_size=256,\
epochs=20,\
validation_data=(X_test,y_test))
深度学习神经网络方法的一大优势是,我们不必尝试和设计特征,因为神经网络将学习上下文和重要特征。
然而,这是以可解释性为代价的——这在某些情况下是一个重大限制。此外,就计算时间而言,它是最昂贵的方法,特别是如果词嵌入是联合训练的,因为它需要大量数据集。
对于我们的数据集,词嵌入LSTM模型(参数为61MM)需要20小时的训练。它确实产生了96%准确率的显著训练分数和80%准确率的测试/验证分数。
情感分析应用
如果操作正确,情感分析可以为任何组织提供巨大的价值。如今,组织使用情感分析来了解公众对其产品、服务和品牌的感受。这可以指导营销策略,激发产品开发,为政治活动提供信息,并发现潜在的破坏性事件。以下是一些经过验证的示例:
- 确定潜在的诋毁者,以便进行优先排序,以提高NPS(客户关怀/反馈分析)
- 快速评估客户参与情况,以识别和解决负面客户体验,从而改进客户服务和提高回头率
- 监控和管理公众对品牌的情绪(品牌智能)
总结并选择正确的工具
我们回顾了情感分析的三种方法,每种方法都有各自的优缺点。在选择合适的方法时,需要考虑以下几点:
- 精度和速度?如果速度优先于准确性,那么基于规则的解决方案可能是正确的解决方案。
- 训练数据的可用性和完整性?对于健壮的训练数据,朴素贝叶斯模型可以是正确的解决方案,因为它实现起来很快。
- 模型的可解释性有多重要?如果精确性优先于模型的可解释性,那么深度学习可能是正确的解决方案。
并行运行多个模型以进行比较并不少见。一旦部署,流程应该包括一个反馈循环,以通知何时需要更新模型。
我还致力于分享如何通过并行计算更快地训练NLP模型的代码。
感谢阅读! |
|



 发表于 2023-6-30 15:04:01
发表于 2023-6-30 15:04:01