|
|
摘要
本系统基于机器学习方法进行文本情感分析研究,实现对语言文本的情感分析,数据集有中英文共64475条数据,包括高兴、伤心、恶心、生气、害怕、惊讶等6中情感,分析准确率在98%以上。
先看一段demo
https://www.zhihu.com/video/1585308419980025857
1、实验流程
实验流程图:
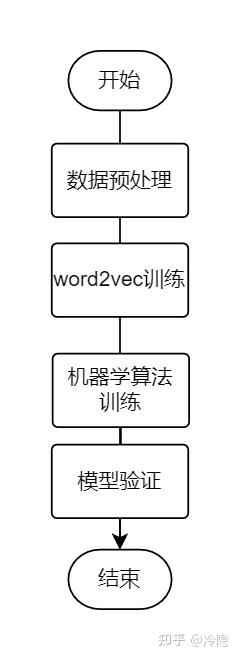
实验流程图
具体而言,数据预处理过程包括数据清洗、分词、去停用词等;word2vec将文本训练成词向量形式;机器学习算法训练,将数据集以7:3比例划分训练集和验证集,训练集用于训练模型,验证集用于下一步骤模型验证,来测试模型效果,使用混淆矩阵、精准率、召回率、F1值来验证模型性能。
2、代码实现
先来看看数据集的样子

每一行是一条数据
前面的数据是情感标签,分别为高兴0、伤心1、恶心2、生气3、害怕4、惊讶5
首先导入需要的工具包,各工具包用途注释已经给出
from Segment_ import * #zhcnSegment自己编写的数据预处理模块,包含分词等功能
import pandas as pd # pandas、csv、numpy是读取文件或处理数组等工具包
import csv
import numpy as np
import time # 获取时间
from sklearn import svm # sklearn工具包导入支持向量机算法
from sklearn.model_selection import train_test_split #从sklearn工具包导入数据集划分工具
from sklearn.metrics import f1_score,confusion_matrix #从sklearn工具包导入评价指标:混淆矩阵和f1值
from classification_utilities import display_cm #给混淆矩阵加表头
import joblib #储存或调用模型时使用
import multiprocessing #多进程模块
import PySimpleGUI as sg #gui工具包
import gensim # 从gensim工具包中导入Word2Vec工具包
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
import warnings #忽略告警
warnings.filterwarnings(action='ignore', category=UserWarning, module='gensim') 1、数据预处理
def read_data():
wds = Seg()
# 分词后的数据集存放在data文件夹中data.seg.txt里
target = codecs.open('./data/data.seg.txt', 'w', encoding='utf8')
# 待分词文档导入
with open('./data/data.txt',encoding='utf8') as f:
lineNum = 1
line = f.readline()
# 逐行进行分词处理
while line:
seg_list = wds.cut(line, cut_all=False)
line_seg = ' '.join(seg_list)
target.writelines(line_seg)
lineNum = lineNum + 1
line = f.readline()
f.close()
target.close()2、训练word2vec
先定义返回特征词向量和构建文档词向量两个函数
# 返回特征词向量
def getWordVecs(wordList, model):
vecs = []
for word in wordList:
word = word.replace('\n', '')
try:
vecs.append(model[word])
except KeyError:
continue
return np.array(vecs, dtype='float')
# 构建文档词向量
def buildVecs(filename, model):
fileVecs = []
with codecs.open(filename, 'rb', encoding='utf-8') as contents:
for line in contents:
wordList = line.split(' ')
vecs = getWordVecs(wordList, model)
if len(vecs) > 0:
vecsArray = sum(np.array(vecs)) / len(vecs) # mean
fileVecs.append(vecsArray)
return fileVecs训练word2vec
# inp为输入语料, outp1 为输出模型, outp2为原始c版本word2vec的vector格式的模型
fdir = './data/'
inp = fdir + 'data.seg.txt'
outpbi = fdir + 'data.seg.text.bin'
outp1 = fdir + 'data.seg.text.model'
outp2 = fdir + 'data.seg.text.vector'
# 训练skip-gram模型
model = Word2Vec(LineSentence(inp), size=100, window=5, min_count=5,
workers=multiprocessing.cpu_count())
# 保存模型
model.wv.save_word2vec_format(outpbi, binary=True)
model.save(outp1)
model.wv.save_word2vec_format(outp2, binary=False)根据上面的模型 得到本数据集的文本向量
inp22 = fdir + 'data.seg.text.vector'
model22 = gensim.models.KeyedVectors.load_word2vec_format(inp22, binary=False)
Input22 = buildVecs(fdir + 'data.seg.txt', model22)
f = codecs.open('./data/data.seg.txt', mode='r', encoding='utf-8')
line = f.readlines()
data = pd.concat([df_y, df_x], axis=1)
# 将结果保存在data.csv文件里面
data.to_csv(fdir + 'data.csv')下面就是机器学习训练和验证过程了
def classification_():
# 读取数据
df = pd.read_csv('./data/word2vec.csv')
# 读取标签
y = df.iloc[:, 1]
# 标签对应的情感
labels = ['joy', 'sadness', 'disgust', 'anger', 'fear', 'surprise', ]
# 读取数据
x = df.iloc[:, 2:]
# 将训练集划分训练、验证两部分
X_train, X_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=42)
print('支持向量机....')
clf = svm.SVC(C=100, probability=True)
clf.fit(X_train, y_train)
joblib.dump(clf, "model.m")
print('混淆矩阵')
cv_conf = confusion_matrix(y_test, clf.predict(X_test))
display_cm(cv_conf, labels, display_metrics=True, hide_zeros=False)
micro_f1 = f1_score(y_test, clf.predict(X_test), average='micro')
macro_f1 = f1_score(y_test, clf.predict(X_test), average='macro')
print('macro_f1', macro_f1)
print('micro_f1', micro_f1)
print('准确率: %.2f' % clf.score(x, y))
print('..................................')
实验结果
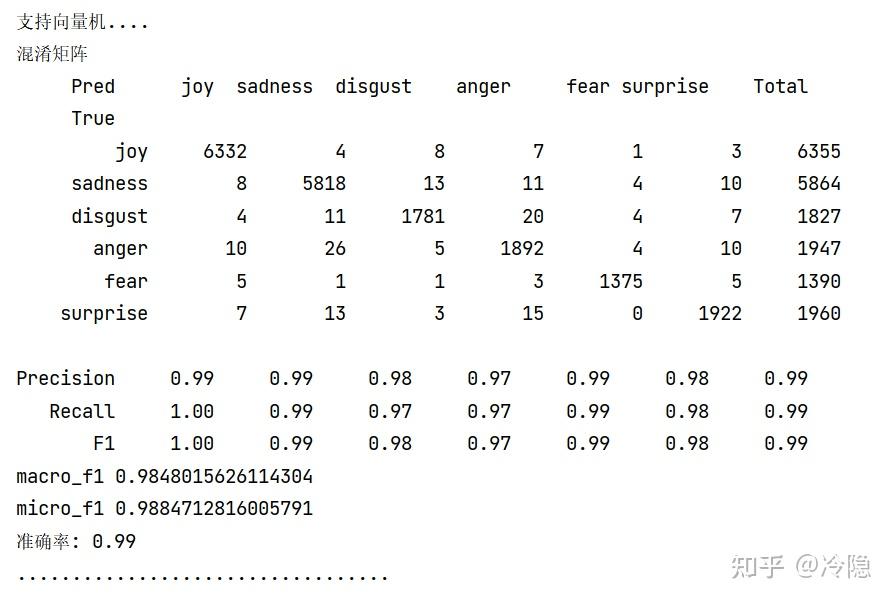
识别效果不错
单条文本的识别
def predict_(a):
inp = './data/data.seg.text.vector'
model = gensim.models.KeyedVectors.load_word2vec_format(inp, binary=False)
wds = Seg()
seg_list = wds.cut(a, cut_all=False)
line_seg = ' '.join(seg_list)
line_seg = line_seg.split(' ')
vecs = getWordVecs(line_seg, model)
if len(vecs) > 0:
vecsArray = sum(np.array(vecs)) / len(vecs) # mean
clf = joblib.load("model.m")
vecsArray = vecsArray.reshape(1, 100)
kk = clf.predict(vecsArray)
if kk == [0]:
return "表达开心"
if kk == [1]:
return "表达伤心"
if kk == [2]:
return "表达恶心"
if kk == [3]:
return "表达生气"
if kk == [4]:
return "表达害怕"
if kk == [5]:
return "表达惊喜"
else:
return "表达中性情感"算法部分到这就可以结束了,后面是可视化界面搭建的过程,我使用的是PySimpleGUI工具包,理由只有一个,那就是简单好用,两三个小时就能从零到入门,缺点就是界面太丑了,只能是能用,话不多说,直接看代码吧
主窗口的搭建:
def make_window(theme):
sg.theme(theme)
# 菜单栏
menu_def = [['Help', ['About...', ['你好']]], ]
# 主界面之一:文本识别界面
News_detection = [
[sg.Menu(menu_def, tearoff=True)],
[sg.Text('')],
[sg.Multiline(s=(60, 20), key='_INPUT_news_', expand_x=True)],
[sg.Text('')],
[sg.Text('', s=(12)), sg.Text('识别结果:', font=("Helvetica", 15)),
sg.Text(' ', key='_OUTPUT_news_', font=("Helvetica", 15))],
[sg.Text('')],
[sg.Text('', s=(12)), sg.Button('识别', font=("Helvetica", 15)), sg.Text('', s=(10)),
sg.Button('清空', font=("Helvetica", 15)),
sg.Text('', s=(4))],
[sg.Text('')],
[sg.Sizegrip()]
]
# 主界面之二:文本识别内容的管理,可以查看自己识别的内容
News_management = [
[sg.Table(values=read_table_data('./data/table_data.csv')[1:][:], headings=['文本内容', '识别时间', '识别结果'],
max_col_width=30,
auto_size_columns=True,
display_row_numbers=False,
justification='center',
num_rows=20,
alternating_row_color='LightGrey',
key='-TABLE_de-',
selected_row_colors='red on yellow',
enable_events=True,
expand_x=True,
expand_y=True,
vertical_scroll_only=False,
enable_click_events=True, # Comment out to not enable header and other clicks
)
],
[sg.Button('删除选中的结果', font=("Helvetica", 15)), sg.Button('查看识别结果', font=("Helvetica", 15))],
[sg.Sizegrip()]
]
empty = []
layout = [[sg.MenubarCustom(menu_def, key='-MENU-', font='Courier 15', tearoff=True)],
[sg.Text('中英文情感识别系统', size=(50, 1), justification='center', font=("Helvetica", 16),
relief=sg.RELIEF_RIDGE, k='-TEXT HEADING-', enable_events=True, expand_x=True)]]
layout += [[sg.TabGroup([[
sg.Tab(' 文 本 识 别 ', News_detection),
sg.Tab(' ', empty),
sg.Tab(' 结 果 管 理 ', News_management,element_justification="right",)]],
expand_x=True, expand_y=True,font=("Helvetica", 16)),
]]
window = sg.Window('中英文情感识别系统', layout,
right_click_menu_tearoff=True, grab_anywhere=True, resizable=True, margins=(0, 0),
use_custom_titlebar=True, finalize=True, keep_on_top=True)
window.set_min_size(window.size)
return window界面中的功能函数:
def main():
window = make_window(sg.theme())
while True:
event, values = window.read(timeout=100)
if event in (None, 'Exit'):
print("[LOG] Clicked Exit!")
break
elif event == '识别':
kk = predict_(values['_INPUT_news_'])
time2 = time.strftime('%Y-%m-%d %H:%M:%S')
newuser = [values['_INPUT_news_'], time2, kk]
with open('./data/table_data.csv', 'a', newline='') as studentDetailsCSV:
writer = csv.writer(studentDetailsCSV, dialect='excel')
writer.writerow(newuser)
window['_OUTPUT_news_'].update(kk)
window["-TABLE_de-"].update(values=read_table_data('./data/table_data.csv')[1:][:])
elif event == '清空':
window['_OUTPUT_news_'].update(' ')
window['_INPUT_news_'].update('')
elif event == '查看识别结果':
window["-TABLE_de-"].update(values=read_table_data('./data/table_data.csv')[1:][:])
elif event == '删除选中的结果':
data = pd.read_csv('./data/table_data.csv', encoding='gbk')
data.drop(data.index[int(values['-TABLE_de-'][0])], inplace=True)
# 如果想要保存新的csv文件,则为
data.to_csv("./data/table_data.csv", index=None, encoding="gbk")
window["-TABLE_de-"].update(values=read_table_data('./data/table_data.csv')[1:][:])
window.close()
exit(0)3、总结展望
在深度学习方法bert、transform方法大杀四方的时候,机器学习方法、word2vec似乎用的人很少了,但是就效果而言,传统方法也不是一无是处,深度学习是机器学习中的一种方法,了解基本的机器学习流程,对深度学习一样有帮助。 |
|



 发表于 2023-1-17 15:51:55
发表于 2023-1-17 15:51:55